
Service Schaden Digital
Im Jahr 2020 startete unsere neue Abteilung Digitale Services in der HUK-COBURG. Der zentrale Auftrag der Abteilung ist, kundennahe Dienstleistungen mit modernster Technik zu unterstützen, um innovative und einfache Lösungen zu generieren.
Hier positioniert sich auch der Service Schaden Digital, der mit der Bereitstellung von intuitiven Schadenservices einen hohen fachlichen sowie technischen Automatisierungsgrad erzielen möchte. Dieser hohe Automatisierungsgrad soll durch eine hohe Verfügbarkeit der bereitgestellten Dienstleistungen gestützt werden. Teil der Mission ist, alte Technologien abzulösen, um mit modernen Architekturen zukunftssichere und wartungsarme Prozesse softwaregestützt realisieren zu können.
Der Fokus in der Mission rund um die Automatisierung liegt auf den Bedürfnissen des Kunden, die als zentrale Qualitätskriterien definiert sind. Dadurch ergibt sich auch ein starker Fokus auf User Experience, um dem Kunden die bestmögliche Erfahrung bieten zu können.
Inhaltsverzeichnis
Der Weg in die Cloud
Auf Basis eines modernen Technologiestacks haben wir im Jahr 2020 begonnen, containervirtualisierte Anwendungen on premises innerhalb der HUK-COBURG zu betreiben. Hier kommen vorwiegend Java Application Server in den Backends zum Einsatz, während die Frontendapplikationen als Single Page Applications als statische Ressourcen ausgeliefert werden. All das geschieht auf geteilter Hardware in einem Rechenzentrum on premises. Dabei wollten wir einerseits Prozesse fachlich frei und andererseits technologisch neu denken.
On premises werden häufig zentrale Komponenten genutzt, auf die unser eigentliches Team keinen direkten Einfluss hat. Somit ist die Möglichkeit DevOps eigenverantwortlich mit einer Ende-zu-Ende-Verantwortung betreiben zu können relativ limitiert, da Anwendungsbetreuer der zentralen Komponenten häufig nicht direkt in unseren Teams präsent sind.
Neben der Ende-zu-Ende-Verantwortung im gesamten DevOps-Prozess führte uns auch die Verwendung geteilter Ressourcen zu Überlegungen, wie die Unabhängigkeit und Eigenständigkeit unseres Teams gesteigert werden kann.
Auf Basis dieser Überlegungen kamen wir 2021 zu der Entscheidung, einen ersten Anwendungsfall bei einem Cloud Service Provider (CSP) zu implementieren. Somit könnten wir die Verfügbarkeit hochhalten, die vollständige Verantwortung für den Anwendungsfall übernehmen – sowohl im Code, als auch in der Infrastruktur – und eine Ebene der Unabhängigkeit zu weiteren Prozessen und benachbarten Services etablieren.
Entscheidung für AWS
Zum Start des Vorhabens, die Dienste auf eine neue technologische Basis zu stellen, haben wir uns nach einem umfangreichen Auswahlprozess, Sicherheitsbetrachtung und der Entwicklung von Fallback- und Exitszenarien für Amazon Web Services (AWS) entschieden.
On premises setzen wir stark auf den Betrieb in einer private Cloud. Hier entwickeln wir vorwiegend containerbasierte Anwendungen, die für den Betrieb in der Containerorchestrierung überführt werden.
Die Idee der Entwicklung in der Cloud, folgte den Paradigmen den Betrieb möglichst nativ in den Infrastrukturkomponenten des CSP zu realisieren. Basierend darauf haben wir möglichst vermieden ein Kubernetes innerhalb eines CSP zu nutzen, um hier keinen private Cloud-Betrieb auf einer public Cloud umzusetzen.
In AWS sollten auf Basis eines Technologiestacks direkt serverless Anwendungen entwickelt werden, die direkt integrierbar sind. Ein weiteres Ziel war die Auslieferung der statischen Ressourcen auf Basis von nativen Methoden des CSP, um die Infrastruktur on premises entlasten zu können.
Für die entsprechenden Herausforderungen war unser Ziel, möglichst viele "best practices" und Standardwege innerhalb von AWS zu beschreiten, um einerseits Standardarchitekturen zu verwenden und andererseits den Einbau von Spezifika zu reduzieren, die erhöhte Pflegeaufwände im Aktualisierungsfall und ausführliche Dokumentation erfordern.
AWS selbst bietet für den Betrieb von serverless Anwendungen Lambda als Function as a Services (FaaS) Framework für den Betrieb von Services in verschiedenen Sprachen an. Für die Auslieferung der statischen Ressourcen, konnten wir die Standardkomponenten CloudFront als Content Delivery Network (CDN) und den Simple Storage Service (S3) nutzen.
Auf Basis dieser generellen Verfügbarkeit und der leichten Integrationsmöglichkeit der Infrastrukturkomponenten, waren wir in der Lage, viele verschiedene Anwendungsarchitekturen realisieren zu können, die bezüglich der Implementierung und dem Einsatz der vorhandenen Frameworks auch problemlos möglich waren.
Wie unser Weg mit AWS in die Cloud weitergeht, erfahrt ihr im nächsten Beitrag von mir.
Veröffentlicht am 9. September 2022 – Autor: Carsten Kropf
Der Weg in AWS
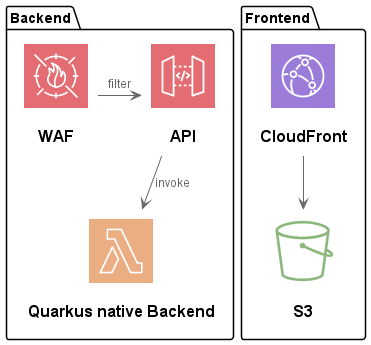
Wir haben AWS als Cloud Service Provider für unseren Service Schaden Digital ausgewählt. Unser zentrales Ziel dabei ist, auf Basis von cloud nativen Technologien in AWS serverless zu arbeiten. Die Betriebsmodelle von cloud nativen Anwendungen unterscheiden sich vom Containerbetrieb, der on premises zum Einsatz kommt, wodurch die Rückportierung der Anwendungen herausfordernd ist. Wir haben uns jedoch dazu entschieden, einen möglichst hohen Kompatibilitätsgrad zu den Bestandsanwendungen sicherzustellen.
Im Backend wird Jakarta EE genutzt, um Microservices innerhalb von Containern auf Application Servern zu betreiben. Der Betrieb von Container kollidiert jedoch mit dem Ziel cloud native Technologien serverless einzusetzen.
Um die Kompatibilität mit Jakarta EE sicherzustellen, verwenden wir Quarkus. Dadurch eröffnet sich uns die Möglichkeit, eine native ahead-of-time Kompilierung durchzuführen, was die Startzeit signifikant reduziert. Dieser Aspekt ist gerade bei der Verwendung von serverless Applikationen extrem wichtig. Bei Nichtverwendung werden die Anwendungen beendet und, wenn benötigt, erneut gestartet. Weiterhin kann eine Quarkus Applikation mit geringem Aufwand Lambda und Containerbetrieb vereinen und es ist ebenfalls ein mögliches Ausstiegs-Szenario gegeben, da die Anwendungen potenziell leicht in einem Container on premises betrieben werden können.
Die Auslieferung der Frontendanwendungen geschieht in einem Content Delivery Network (CDN), das auf die Artefakte in einem S3 Bucket zugreift und pfadbasiert zu diesen Artefakten routed. Das Routing funktioniert analog zu dem Verfahren, das bereits im Haus im Einsatz ist. Somit ist für die Frontendanwendungen sichergestellt, dass diese on premises betrieben werden können.
Die zentralen Komponenten innerhalb von AWS stellen Lambda für serverless Applikationen und CloudFront als CDN dar. Neben diesen Services nutzen wir noch weitere Dienste zur Applikationsintegration:
- API Gateway mit OpenAPI
- S3 zur Ablage von Artefakten und statischen Assets
- Route53
- ACM
- SecretsManager
Wir verwenden die angebotenen Managed Services für die Verbindung der Infrastrukturkomponenten und Kommunikationskanäle auf Basis von Standardkonfigurationen innerhalb von AWS.
Während der Migration und der Entwicklung in Richtung AWS zeichnete sich für uns als Team ab, dass die Rückportierung in Richtung on premises nicht trivial ist. Allerdings bleiben die Programmiersprachen und Frameworks identisch, um ein schnelles Onboarding und eine unkomplizierte Verbreitung der Technologien im Unternehmen zu ermöglichen.
Außerdem dokumentieren wir sämtliche Anpassungen und Entscheidungen nachvollziehbar und automatisiert und verfolgen dabei den Ansatz des *-as-Code und behandeln Quelltext, Infrastruktur sowie Dokumentation mit denselben Verfahren.
Über die Automatisierung sowie die Integration erfahrt ihr mehr in meinem nächsten Beitrag.
Veröffentlicht am 14. November 2022 – Autor: Carsten Kropf
Automatisierung
Im Service Schaden möchten wir einen hohen Automatisierungsgrad für die Generierung und Überwachung aller Komponenten realisieren. Dabei ist es für uns wichtig, die Schritte manueller Eingriffe zum Liefern der Software auf ein notwendiges Minimum zu reduzieren. Die Cloud Service Provider stellen APIs zur Provisionierung, Konfiguration und Überwachung der entsprechenden Infrastrukturkomponenten bereit. Neben der Automatisierung ist es uns wichtig, Nachvollziehbarkeit der getätigten Aktionen und Zustände zu gewährleisten.
Durch diese Anforderungen haben wir einen *-as-Code Ansatz gewählt, der sowohl die entstehenden Artefakte, als auch die Infrastrukturkomponenten und Dokumentation umfasst. Wir verwalten alle diese in einem git Server bei dem die Quellen automatisiert über einen Buildserver publiziert werden. Die Infrastrukturbeschreibungen werden in einem ähnlichen Prozess angewandt.
Aus einer zentralen Ablage heraus werden die entsprechenden Artefakte, z. B. in AWS, übertragen und in Ablagen, wie S3, bereitgestellt. Dies stellt die Grundlage für den Infrastructure-as-Code (IaC)-Schritt dar.
Mithilfe von IaC, in diesem Fall terraform, provisionieren wir die Änderungen basierend auf einem GitOps Ansatz in AWS. Dadurch stellen wir dem Kunden die Anwendungen zur Verfügung.
Auch die Dokumentation wird bei uns vollautomatisiert erstellt. Diese liegt im selben Repository wie der Quelltext der Applikation bzw. Infrastrukturkonfiguration und wird von dort an die entsprechenden Zielsysteme publiziert. Daraus ergibt sich folgender Vorteil: Der Entwickler bearbeitet die Dokumentation am Erstellungsort des Codes, sie kann aber trotzdem in einem zentralen System gelesen werden.
Diese Maßnahmen ermöglichen uns eine nachvollziehbare, automatisierte und gut dokumentierte Anwendungslandschaft. Sie kann leicht auf vorherige Zustände zurückgesetzt werden, falls sich Fehler nach einer Änderung der produktiven Infrastruktur ergeben.
Veröffentlicht am 20. Januar 2023 – Autor: Carsten Kropf
Ausbildung und Schulung
Während der Implementierung der ersten Anwendung innerhalb von AWS lernten wir sehr viel im Selbststudium, durch Diskussionen und Anwendungen von vorhandenen Methoden. Weiterhin existierte sehr viel Unterstützung seitens AWS, die Beratungsleistung, Hands-on-Sessions und auch aktive Hilfe zur Verfügung stellten.
Die Prozesse zur Lieferung und zum Deployment der Artefakten haben wir nach bekannten Ansätzen für uns vollständig neu überdacht und auf Basis von Literatur umgesetzt. Hier haben wir versucht, möglichst nah an den Standardansätzen mit Blue-Green Deployments und GitOps zu arbeiten und auch die Standardinfrastrukturkomponenten mit deren vorgesehener Funktionalität zu nutzen.
Neben dem Selbststudium und der Nutzung von Standardansätzen wurden uns parallel seitens AWS Solution Architects deep dive Sessions und Whiteboardings angeboten, um die gegebenen Herausforderungen unter Zuhilfenahme von AWS Komponenten bzw. vorhandenen well architected Ansätzen anzugehen. Parallel dazu wurde ein Schulungsprogramm für das Ziel der Zertifizierung entworfen. Bei dem Schulungsprogramm wurden zunächst grundsätzliche Einheiten zu technischen Grundlagen und Bedienung von AWS angeboten.
Die weiteren Schulungen umfassten die fortgeschrittenen Schulungen für Entwickler, Architekten und System Operations. Diese umfassten drei Tage und lieferten viele Aspekte für die tägliche Arbeit und auch weiterführende Themen und praktische Anwendungen in den jeweiligen Bereichen.
Jeder meiner Kollegen im Service Schaden Digital hatte die Möglichkeit an mindestens einer der angebotenen weiterführenden Schulungen teilzunehmen und somit die Vorbereitung für eine Zertifizierungsprüfung zu nutzen.
Ausblick
Durch die Migration in die Cloud haben wir sehr viel im Bereich DevOps gelernt, indem wir versuchten, anhand von Standardansätzen einen möglichst einheitlichen und standardisierten Prozess zu ermöglichen.
Die entwickelten Prozesse können sehr leicht skaliert werden, wodurch die Implementierung neuer Anwendungsfälle in der Cloud für uns sehr einfach ermöglicht wird.
Weiterhin haben wir die Möglichkeit, die Alarmierung und Ereignisse eigenverantwortlich zu bearbeiten und die Kosten im Blick zu behalten.
Unser Zielbild im Jahr 2023 ist, das Gelernte auf weitere Anwendungen im Bereich Schaden zu portieren und stetig weiterzuentwickeln. Außerdem werden sich neue Anforderungen ergeben bei denen wir versuchen, mit vorhandenen Infrastrukturkomponenten und Services des CSP, eigene angepasste Implementierungen zu verschlanken. Beispielhaft hierfür ist die Einführung eventgetriebener Kommunikation und Erhöhung der Resilienz. Weiterhin ist die Kostenoptimierung sowie die Erweiterung des Monitorings, sowohl technisch als auch fachlich, eines unserer Ziele für die Weiterentwicklung der Nutzung von cloud nativen Systemen.
Die Erfahrungen in der Cloud nativen Entwicklung wollen wir anhand neuer Arbeitsmethoden, z. B. Mob Programming, auf alle Teams in unserem DS Service verteilen und anhand des Gelernten auch andere Services und Teams ermutigen und befähigen, den Weg in die Cloud zu wagen.
Veröffentlicht am 03. Mai 2023 – Autor: Carsten Kropf

Du hast Lust, mich und meine Abteilung zu unterstützen?
Wir suchen noch IT-Architekten: IT-Architekt:in (Cloud / App)

